
一、系列介绍
经济统计著作系列推文将深入浅出的解读国际上具有影响力的经济统计著作。除出版社出版的经济统计著作以外,也包括国际组织(OECD、UN、World Bank、IMF、EU 等)出版的部分经济统计方法论手册和专题论文集,经济统计学主题的博士论文,经济研究机构的部分Working Paper(工作论文)。
Calderón, José Bayoán Santiago, and Dylan G. Rassier. 2022. Valuing the U.S. Data Economy Using Machine Learning and Online Job Postings. BEA Working Paper Series WP2022-13. US Department of Commerce, Bureau of Economic Analysis.

图1 《Valuing the U.S. Data Economy Using Machine Learning and Online Job Postings》
在数字技术席卷全球生产与消费结构的当下,数据已从附属于软件的“沉默要素”跃升为独立且日益增值的经济资产。然而,这一跃迁尚未在官方统计体系中找到对应坐标。当谷歌、Meta等巨头凭数据驱动的广告与算法交易攫取巨额利润、市值屡创新高之际,这些价值在国家资产负债表上却无迹可寻。官方统计的缺口不仅造成宏观指标的系统性低估,也让政策制定者在评估数字经济规模、制定数据治理框架时缺乏可靠依据。问题的核心在于测度手段的缺位。尽管学界早已指出数据具有生产性、可重复使用和长期收益等资产属性,却始终未能形成一套被统计机构采纳的量化框架。Calderón与Rassier的论文正是在这一背景下展开:他们试图回答一个看似简单却悬而未决的问题——如果把企业自建数据视为资本形成,美国在过去二十年究竟为此投入了多少资源?这些投入又如何在不同行业、不同职业之间分布,并最终反馈到宏观经济增长的脉搏之中?
过去二十年,美国经济经历了两场并行却相互缠绕的深刻变革。一方面,云计算、移动互联与人工智能的叠加创新,让数据从辅助决策的“副产品”升级为直接创造收入的核心生产要素;另一方面,官方统计体系却依然沿用诞生于工业时代的框架,把数据视为“非生产资产”,其价值只在并购交易时以“商誉”之名一闪而过。结果便是,当谷歌、Meta、亚马逊在资本市场合计坐拥数万亿美元市值、每年凭数据驱动业务赚取数百亿美元利润之时,这些价值在国家资产负债表上几乎无迹可寻。政策制定者因此陷入尴尬:既担忧“数字巨头”垄断数据红利,又缺乏量化依据;既高呼“数据是新的国家财富”,却在预算与税制设计中找不到对应的统计条目。
更深层的焦虑来自宏观经济监测的失真。2008 年金融危机后,美国企业部门的固定资产投资结构发生显著变化:传统厂房设备占比持续下降,而无形资产——软件、研发、品牌与组织资本——迅速膨胀。数据资本作为无形资产中最隐秘的部分,却因核算缺位而被整体低估,导致GDP、生产率乃至通胀指标都可能出现系统性偏差。当美联储依据这些“失真”指标调整利率,当财政部依据这些“缺口”制定产业补贴,决策的准确性便悄然受损。
Calderón 与 Rassier 首先面临的是“在哪里看见数据生产”这一方法论难题。传统思路依赖企业问卷,但问卷往往滞后且难以区分研发、软件与数据之间的重叠。于是他们把目光投向了网络招聘广告:这些每天都在更新的文本,其实记录了企业最真实、最即时的需求。作者与 Burning Glass Technologies 合作,获取了 2010–2019 年超过 2.39 亿条美国职位发布,并通过雇主名称与 NAICS 行业代码将每条广告精准映射到企业部门。随后,他们让机器学习模型“阅读”职位描述,用 203 个经过人工清洗的“数据相关技能”——从“数据清洗”到“数据湖架构”——作为探针,判断某一岗位是否涉及数据任务。模型对每条广告输出一个介于 0 与 1 之间的“数据强度分数”,再聚合到职业层面,从而得到每个 SOC 职业在数据任务上的时间占比。为了校准这些分数,本文选取了 17 个“标杆职业”(如数据录入员、统计学家、数据库架构师),通过 Doc2Vec 的余弦相似度计算,把其余职业映射到与标杆的距离,形成一个连续的“数据劳动光谱”。这一光谱第一次让官方统计触及到职业内部的任务细分,而不再被“程序员”或“分析师”这类粗线条标签所遮蔽。
有了职业级的时间占比,下一步是把“劳动时间”转换成“资本成本”。本文沿用 BEA 对自建软件的经典做法:先用劳工统计局的就业与工资统计(OEWS)取得每个职业-行业-年份的平均工资和就业人数,乘以时间占比后得到“数据工资单”;再乘以一个 2.52 的加成系数,把雇主缴纳的福利、资本折旧、中间投入与正常利润一并计入。这里的关键假设是,只有 50% 的最终产出真正形成资产,其余 50% 在当期消耗——这一“资本化率”虽被本文称为“占位符”,却反映了数据价值易逝、迭代极快的行业现实。为了避免与软件、研发重复,他们直接把 BEA 用于估算自建软件的四个核心职业(程序员、系统分析师、软件开发与测试工程师)从数据工资单中整体剔除,并对数据处理与托管业(NAICS 518)再额外下调 50%,以剔除外购数据服务带来的重复计算。经过层层剥离,2002–2021 年累计 2.56 万亿美元的企业自建数据投资最终被识别出来,年均名义增速 4.2%,在 2021 年已占企业知识产权投资的近六分之一。
把 2.6 万亿美元按 NAICS 行业拆分,呈现出与直觉相符却更精确的分布。专业、科学与技术服务业(NAICS 54)以 6,460 亿美元的累计投资高居榜首,相当于把每 1 美元行业增加值中的 2.6 美分重新投入数据建设。金融业紧随其后,3380 亿美元的规模背后是高阶风控模型、实时交易算法与客户画像系统对数据的极度依赖。制造业以 3530 亿美元位列第三,却表现出截然不同的节奏:其投资年均增速仅 2.1%,显著低于服务业,揭示出传统重资产行业在数据资本化道路上的迟疑与渐进。更有趣的是企业管理公司(NAICS 55)——这些总部型控股公司——在 2003–2021 年间以 6.2% 的年均增速成为“黑马”,暗示企业集团在内部治理、供应链协调与跨子公司数据整合上投入巨大。相比之下,农业、采矿与公用事业的投资占比均不足 0.6%。
实证结果表明,美国商业部门在自产数据资产上的年投资额从2002年的840亿美元增长至2021年的1860亿美元,年均名义增长率为4.2%。
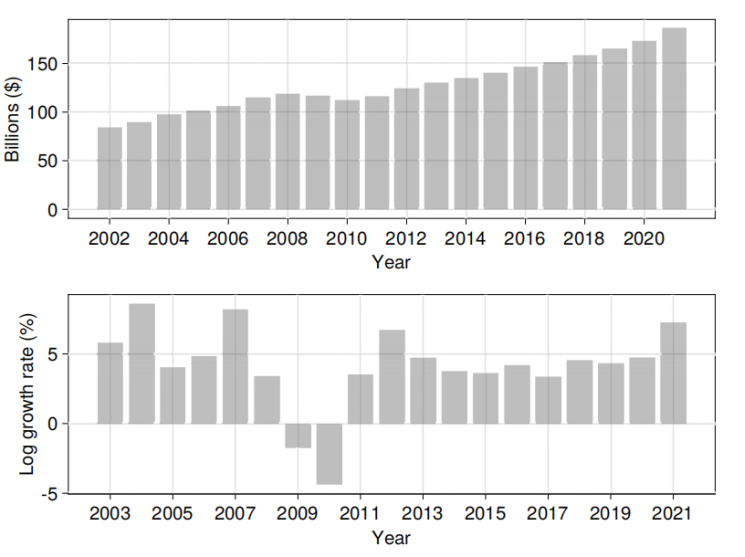
图2 年度数据资产投资额
该期间累计名义投资额达2.6万亿美元。按行业划分,专业、科技与技术服务(NAICS 54)、制造业(31-33)与金融保险业(52)投资规模最大;数据资产对“公司管理业”(NAICS 55)与科技服务业的实际附加值增长贡献最为显著。
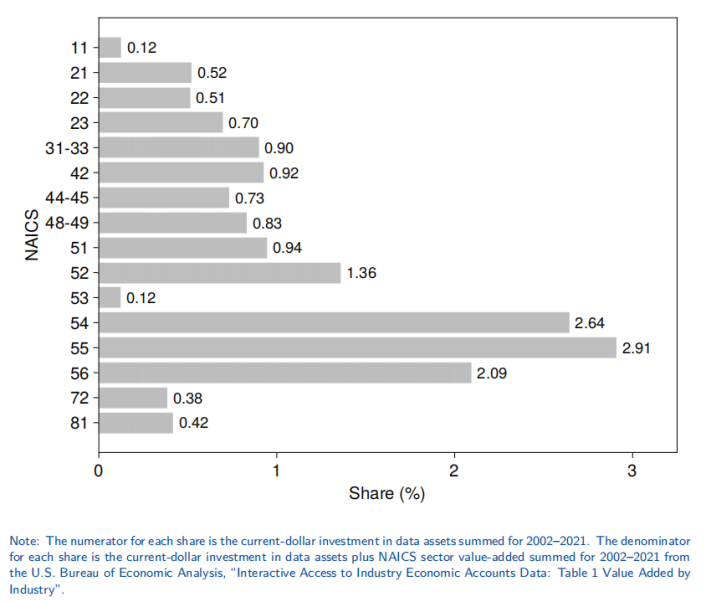
图3 2002–2021年按北美行业分类系统(NAICS)行业划分的数据资产投资占增加值的比例
经价格指数调整后,数据资产投资的年均实际增长率为7.5%,对商业部门实际附加值年增长率贡献4个基点,对IPP投资增长贡献31个基点,相比之下,软件投资增长则出现一定程度下降。
本文的学术价值,首先体现在方法论层面的一次范式迁移:它将机器学习与官方统计传统相融合,把原本模糊的“自建数据资产”拆解为可观测、可复现、可跨国复制的计量路径。本文以 Burning Glass Technologies 的 2.39 亿条招聘广告为语料,训练 Doc2Vec 模型,首次将“职位描述—任务结构—劳动投入”之间的黑箱打开,使“任务级工资”成为资本形成的直接输入。这一流程不仅适用于数据资产,也可迁移至软件、设计、品牌等其他无形资本,为官方统计提供了“大数据+机器学习”的范式级示范。其次,论文在数据层面填补了宏观与微观长期存在的信息断层:通过整合招聘广告、劳工统计局职业就业统计、BEA 行业账户三条异构数据,生成了 2002—2021 年“职业—行业—年份”的面板级时间序列,使学术界第一次拥有一条可回溯、可验证的美国数据资本长期序列,为后续关于数字经济、生产率差异与工资分布的实证研究提供了新的公共基础设施。再次,在制度层面,它为 2025 年联合国 SNA 修订提供了“美国模板”:从数据资本的范围界定、成本估价、重复计算处理到折旧假设,论文给出了可完整落地的操作手册,并以官方身份示范了如何把非市场交易资产纳入国民账户而不破坏现有逻辑,为其他国家降低了技术仿效与政治采纳的双重门槛。
政策意义则体现在把“数据资本”第一次写进了美国宏观经济与治理决策的底稿。华盛顿关于数据跨境流动、反垄断、数字税的辩论长期缺乏量化锚点,本文的估算结果将 2021 年美国企业自建数据投资定格在 1860 亿美元,使财政部得以在宏观模型中重新评估数据基础设施投资的乘数效应;反垄断机构可将“数据资本密集度”作为衡量市场势力的量化指标;国会可依据数据资产折旧率设计云计算与 AI 训练设备的税收优惠;在国际谈判桌上,美国拥有了第一份官方口径的“数据资产国家账”,可直接回应欧盟、OECD 的估算差异,减少“拍脑袋”式的政治博弈。换言之,这篇论文不仅在学术上将数据资产从隐喻转化为可计算、可跨国比较的官方科目,也在政策上为即将到来的全球数据治理与税制重构提供了不可或缺的美国底稿。
作者简介:

José Bayoán Santiago Calderón
José Bayoán Santiago Calderón 现任美国经济分析局(BEA)研究员,主要工作领域为国民经济核算与数字经济量化研究。他于 2019 年在克莱蒙特研究生大学获得经济学博士学位,博士论文聚焦于集群稳健计量模型的理论与应用。在加入 BEA 之前,Calderón 博士曾任弗吉尼亚大学生物复杂性研究所博士后研究员,为联邦及州政府机构提供开源软件与技术劳动力的量化分析;亦曾在私营部门担任高级科学家,负责临床试验设计与监管策略的数据科学支持。其研究专长在于将机器学习、文本挖掘与云计算工具引入官方统计体系,代表性成果包括利用大规模招聘广告构建美国自建数据资产的官方估值框架。此外,他积极参与并推动公共数据科学教育项目,致力于提升行政大数据在宏观经济测度中的可复现性与政策相关性。

Dylan G. Rassier
Dylan G. Rassier 现任美国经济分析局(BEA)国民账户研究部资深经济学家,长期负责数字经济资产核算与跨国企业统计框架的改进。他在明尼苏达大学取得经济学博士学位,研究专长涵盖无形资产估值、全球化对宏观指标的影响以及环境与经济交互计量。作为 BEA 内部技术核心,他主导了美国企业数据资产官方估算项目,为 2025 年联合国 SNA 修订提供了关键的美国模板;同时代表 BEA 向 OECD、G20 及联合国统计司等机构提交专题报告。Rassier 以第一作者在《American Economic Review》《Survey of Current Business》等期刊发表论文,其关于跨国公司利润转移与生产率的研究被广泛引为政策模拟基准,并多次获美国商务部银质与铜质奖章。
图片来源
https://www.bea.gov/research/meet-the-researchers/dylan-rassier
https://www.bea.gov/research/meet-the-researchers/jose-bayoan-santiago-calderon
